第三周
1、神经网络概况
在神经网络中,主要做的事情就是进行反向传播(Backpropagation),比如在逻辑回归中对参数的计算,我们就可以通过损失函数(loss function)进行逆向推导对w和b的值进行优化,然后通过构建一层又一层的神经元,就能完成神经网络的构建。
2、神经网络的表示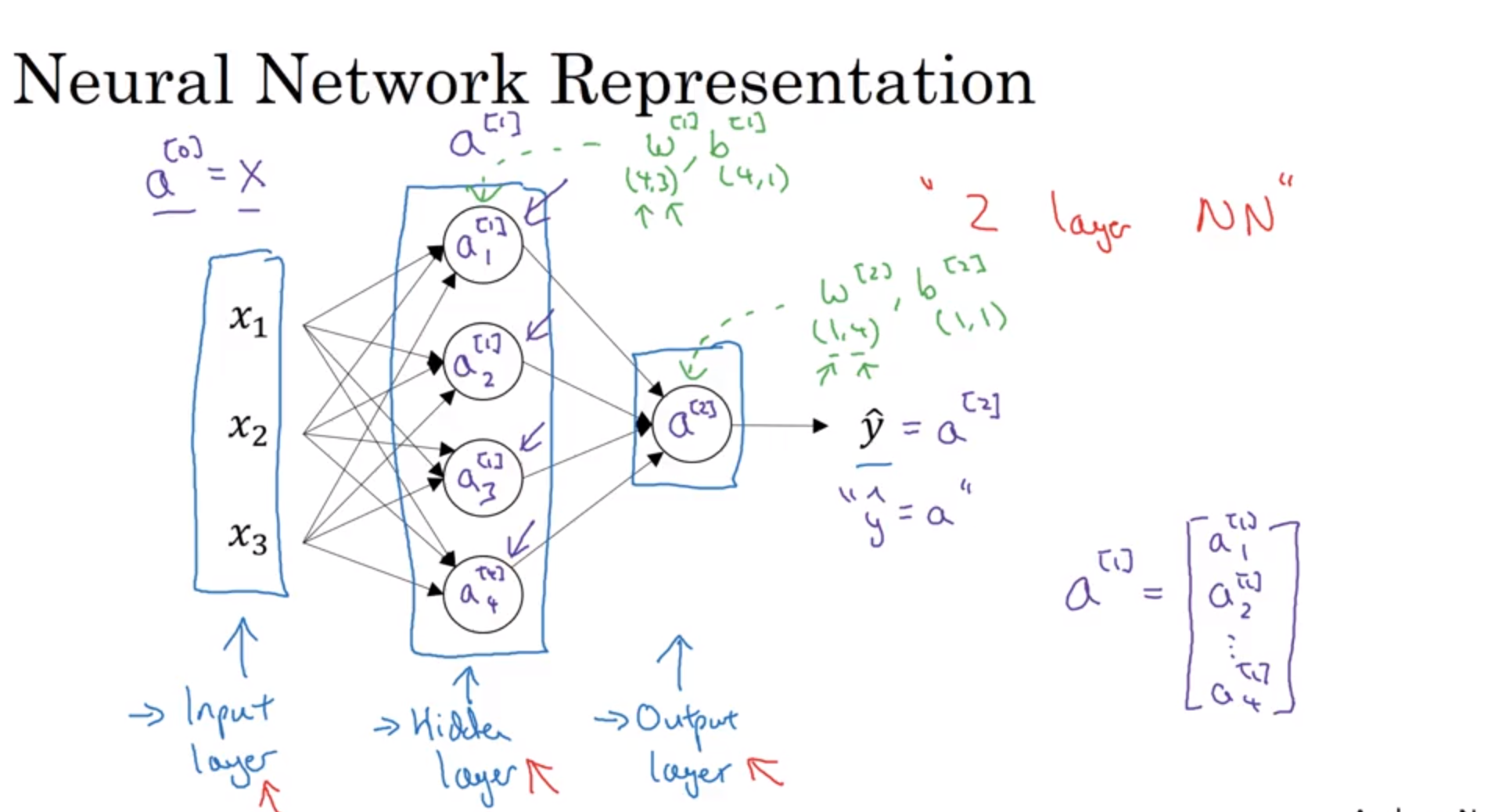
这一节清晰的说明了神经网路的运作形式,其中包括一个输入层(input layer)、隐藏层(hidden layer)以及输出层(output layer)。其中这个隐藏层就是用一堆你想用于计算的函数堆叠起来的,有关隐藏层的解释,我在StackExchange上面看到了这样一个解释。
i.每一个隐藏层能够将各种函数运用在你想处理的前一层数据之中
ii.隐藏层的作用就是将输入转换成输出层能够使用的形式
iii.输出层将隐藏层激活并转化成你想输出的任何规模
除此之外引入了符号a,其中a[0]代表了原本的输入层X,a[1]代表了隐藏层,a[2]代表了输出层。
在做神经网络分层的工作时,输入层不计入,以隐藏层开始计算层数。
3、神经网络的计算方式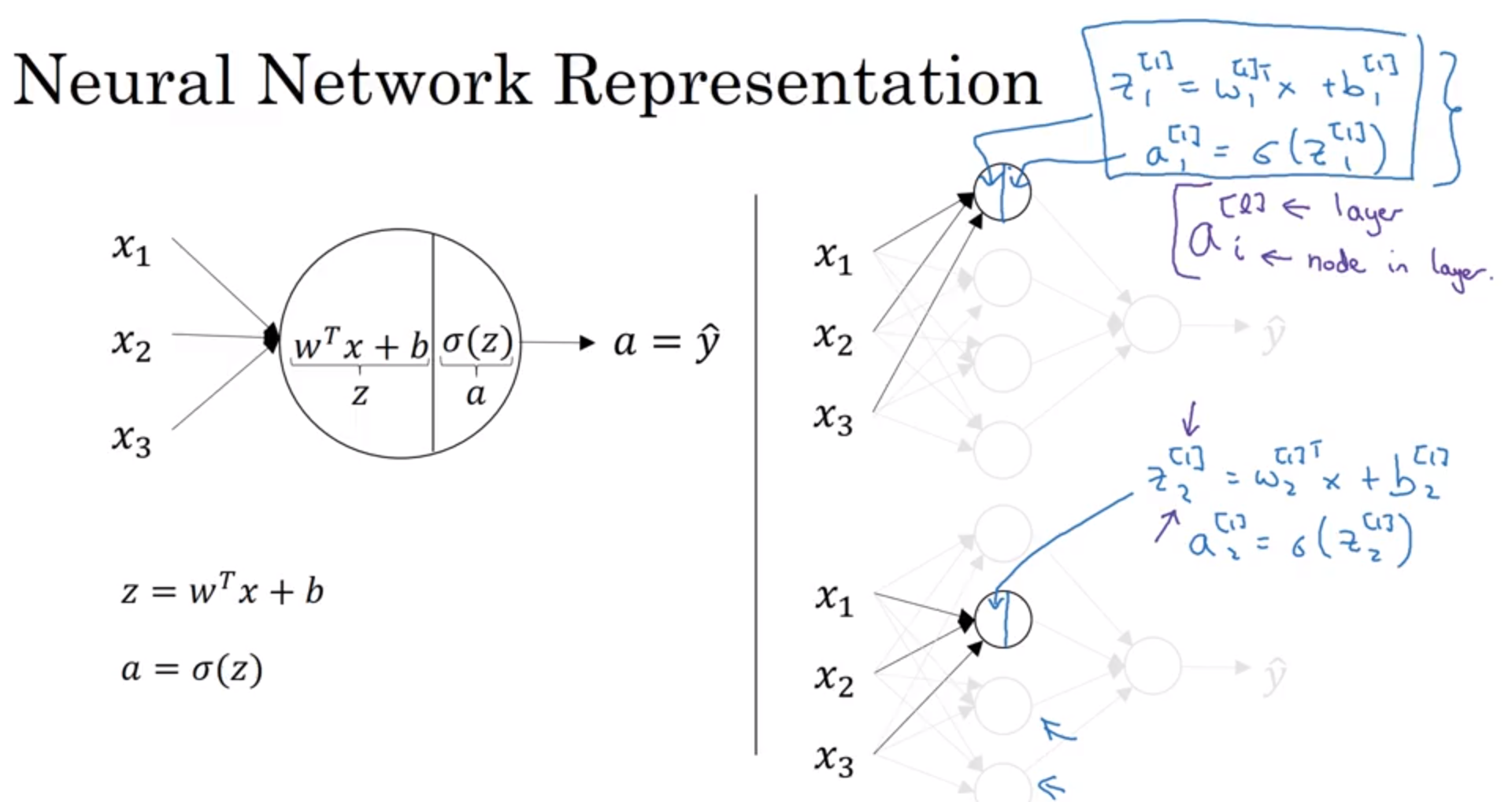
从上面可以看出,左边代表了之前学过的单独的一个神经元如何进行计算的演示,首先是输入层输入了x1、x2以及x3,然后这些数据经过了一个神经元,首先进行线性回归计算,然后通过sigmoid函数计算,最后对数进行输出。那么我们把这个小规模的问题放大,就成了右边所示的计算方式,隐藏层的每一个神经元都在重复左边所作的计算过程。
4、激活函数(Activation functions)
之前我们使用的激活函数都是sigmoid函数,现在我们学习一种新的激活函数tanh函数(tanh function),tanh函数是双曲正切函数,其数学表达式为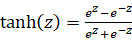
其函数图像为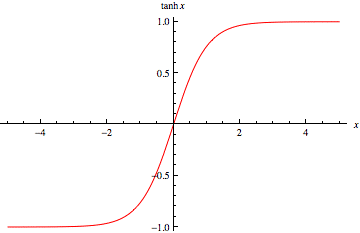
其形状与sigmoid函数类似,不过值域变成了-1到1。可以使用tanh函数以达到数据中心化的目的,所谓数据中心化就是指变量减去它的均值,所以自然希望他们能接近0,而不是sigmoid中的0.5。数据中心化和标准化的好处是得到均值为0,标准差为1的服从标准正态分布的数据。这会使得下一层的学习更加简单,所以除了在二分类中会用到sigmoid函数外,其他时候使用tanh函数具有更好的效果。同时也有选用ReLU函数作为激活函数,ReLU函数在之前已经介绍过。
那么如何选定隐藏层所使用的激活函数呢?一般来说,如果是二分类问题,那么使用sigmoid函数是理所当然的。除了二分类问题外,除非你明确知道需要使用何种激活函数,否则ReLU函数在目前来说是一个广泛且合理的选择。除此之外,ReLU函数还有一个变种,叫做Leaky ReLU函数,它主要的改进就是当z小于0的时候,其值不是和ReLU一样设置为0,而是有一个较小的下降。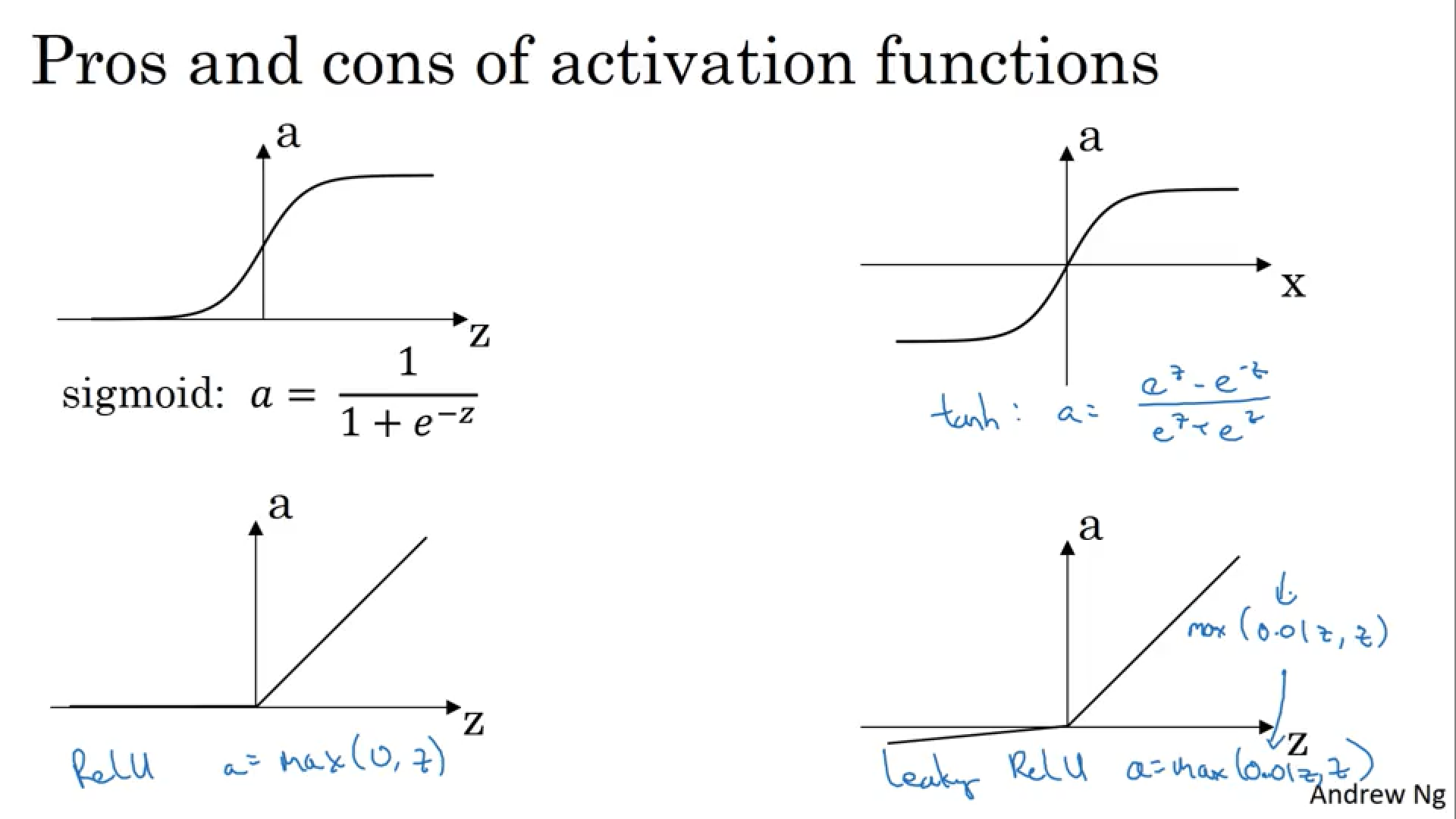
这是有关目前提到的四种激活函数的图像,可以灵活选择。
我们通过图像可以知道,这四种激活函数都是非线性函数,那么问题来了,我们为什么一定得使用非线性激活函数呢?其实使用线性激活函数也是可以的,不过其使用的范围一般是在输出层之中,在隐藏层中一般采用非线性激活函数,因为如果隐藏层中也是线性激活函数的话,那么计算出来的结果也只是输入层的多次线性组合罢了,如果只是多次线性组合,那么这和我们之前所作的逻辑回归方程类似,这还不如直接去掉隐藏层。
5、随机初始化(Random Initialization)
在神经网络中,一般不将权重参数如逻辑回归中一样设置为0。因为在神经网络中,如果设置w和b为0的话,会导致多个神经元的计算重复。所以在神经网络参数初始化的时候,一般采用随机初始化的方式进行,并习惯于从一个非常小的值开始,这是因为较小的值在tanh函数或者sigmoid函数中步长变化比较明显,而如果w一开始就非常大的话,这会导致sigmoid和tanh的变化非常缓慢,不利于学习速率的提升。
补充: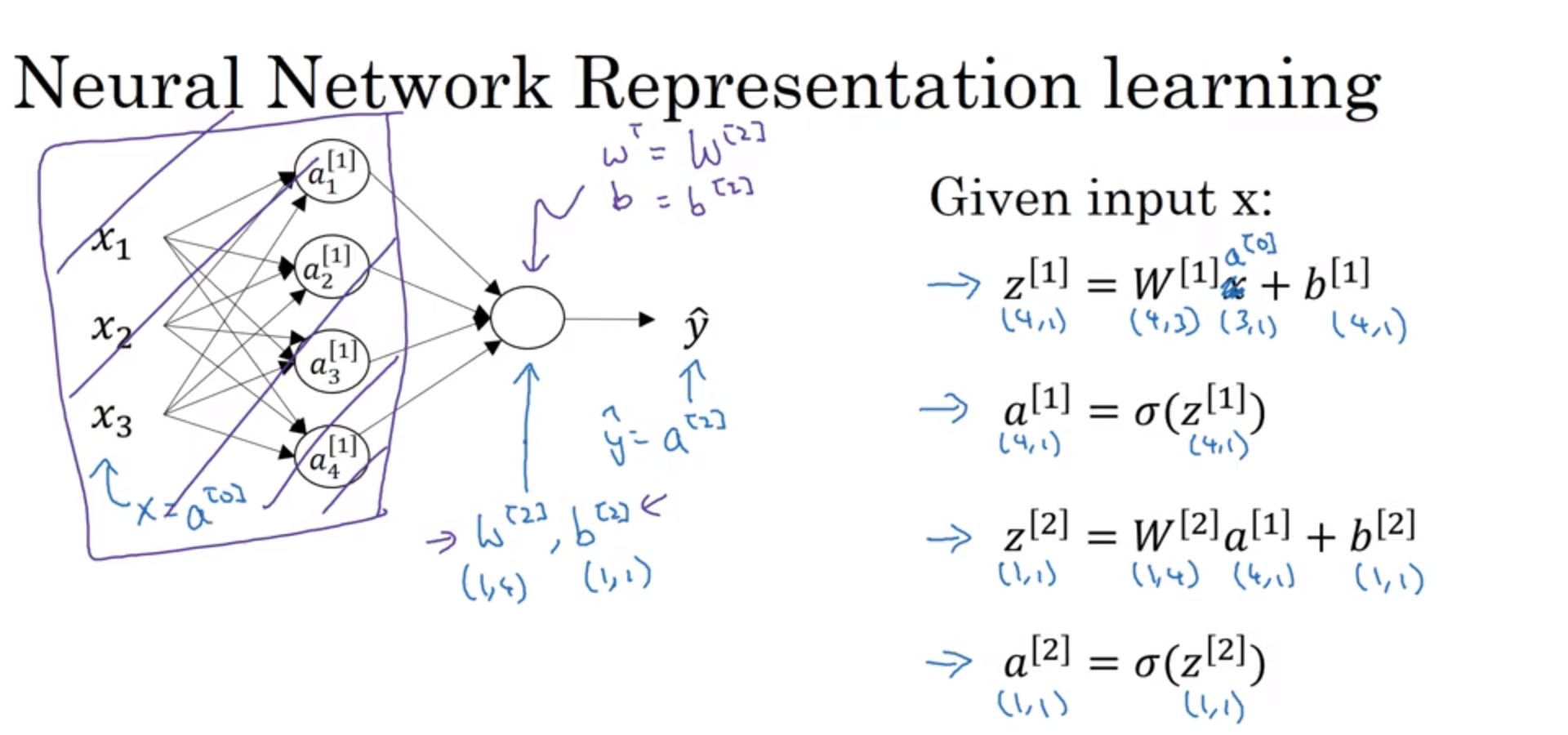
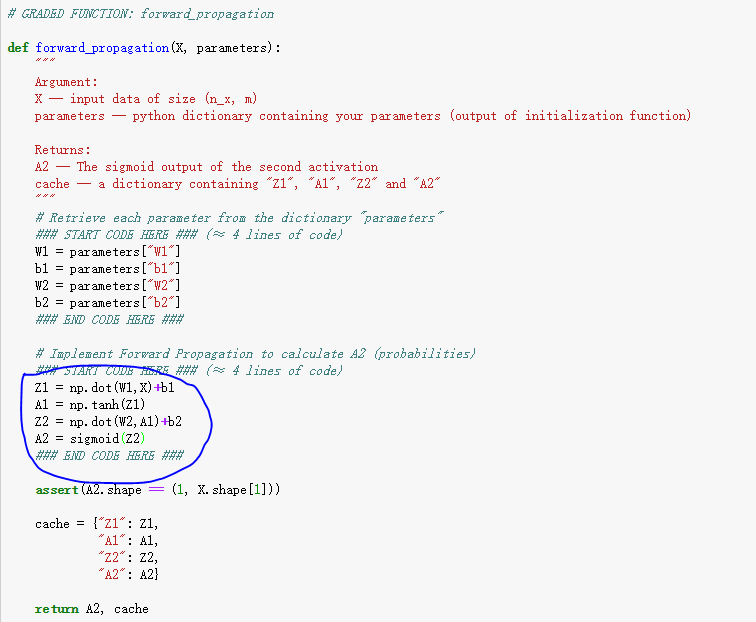
注意在隐藏层之中使用的是tanh函数,而在输出层中使用的是sigmoid函数